Password Cracking (Adopting a reasonable password hygiene)
The main idea is about adopting a better password hygiene. But first, as a motivation, it is important to understand how passwords are stored, leaked and eventually cracked. In short, how vulnerable our various password secured accounts can be.
As an introduction to the field of password cracking, one could mention an interesting post on how an “everyday developer” can crack millions of passwords in one day for less than 20$. One should also watch a very entertaining video with Edward Snowden on passwords. Finally, one can check if our information (web accounts, email addresses and passwords) has been pawned (offered for sale on the dark web) by visiting Have I Been Pwned. That site has information on over 9 billion pawned accounts and half a billion unique cracked passwords (as of 2019-01). We can check if our email address has been pawned, and whether our passwords are already among the lists of cracked passwords, in which case they offer zero protection if targeted.
Summary - TL;DR
How passwords are stored
- Plain text: “secret password” → “secret password”
- Hashed: SHA256(“secret password”) → “1ba133eccdfc4e5ca3…504a4b14c94b8557”
- Salted Hash: sha256(“secret password” + ”B7aU3L”) → “a1296cc48338…045136420”
- Key stretching: pbkdf2( “sha256”, “secret password”, ”B7aU3L”, 100000 ) → “0274d5…82a4”
How passwords are cracked
- Brute force (short password, network of computers, …)
- Use of lexicons + hand crafted rules on human behaviour when creating passwords
- Language models (deep neural networks) (to generate candidate passwords)
- Generative Adversarial Networks (to generate candidate passwords)
Advice
- Use a different password for each account / web site
- Use a passphrase instead of a password (Snowden, Better passwords, Information entropy)
- Use a password management tool (e.g. Bitwarden (open source), NordPass, 1Password)
- Use two factor identification (e.g. Authy, Google Authenticator, FreeOTP)
- Use a VPN app on public Wi-Fis: ProtonVPN, NordVPN, ExpressVPN
Commonly used passwords
Wikipedia has a list of the 10,000 most commonly used passwords, the first five of which are (in alphabetical order): 123256, 123245678, 123456789, password and qwerty. Needless to day, those are not very secure passwords.
I went on to a get a relatively small list of cracked passwords from hashes.org corresponding to a given hacked web site and displayed the first few hundred most frequent ones with a word cloud.

That small list, corresponding to one given hacked site, might not be representative of the passwords in use worldwide, but it is still informative. We can see the usual suspects (those that are part of the 10,000 most commonly used passwords such as: 12345678, 123456789 and password. We can also spot some passwords that seem very hard for a human to remember such as “e10adc3949ba59abbe56e057f20f883e” and “5f4dcc3b5aa765d61d8327deb882cf99”. Those passwords only give a false sense of security to the people who use them, as they are only one known function call away (MD5) from extremely trivial passwords, namely the first two most commonly used passwords: 123456 and password respectively.
123456 --- MD5 ---> e10adc3949ba59abbe56e057f20f883e
password --- MD5 ---> 5f4dcc3b5aa765d61d8327deb882cf99
Password storage
One can consider that there are four password storage schemes, namely plain text, hashed, salted hash and finally key stretching (in order of increased strength). The first three schemes are depicted in the diagram below.

0. Password: Plain text
The first option, plain text, is no scheme at all and should never be used. As the passwords are stored in clear (plain text) in the database, in case of data breaches, all of the login information is readily available for criminals.
When used, it is mostly unintentional (a software bug), like in the case of Twitter in 2018, Facebook in 2019 and Google GSuite in 2019.
Unfortunately, sometimes, plain text is used out of over-confidence in one’s ability as in the case of TMobile Australia in 2018 or Adobe in 2013 (password hints stored in plain text).
1. Password: Hashed
A better solution, the first viable one, is to store the result of passing the password through a cryptographic hash function, which is a one-way function that converts any string into gibberish. One such function is the Secure Hash Algorithm 256 (SHA-256) that converts any string (e.g. a password) into 256 bits of information, which are represented as 64 characters in the range [0..9a..e].
With this scheme, the passwords are never stored in clear plain text. Instead, it is the hashed versions of those passwords (gibberish) that get stored in a database. When a user wishes to log on, the typed password is hashed and then compared with the value stored in the database for that given user. The passwords are never explicitly compared; it is the hashes that are compared.
Note that it is a key requirement for a cryptographic hash function that two different passwords are extremely unlikely to be converted to the same hash value. Such an event would be called a collision.
The key advantages of hashing are that there is no need to ever store the passwords in clear text. A very good cryptographic hash function is required in order to ensure that the probability of a collision (two passwords hashing to the same value) is extremely low.
While it is a major step up from storing passwords in clear text, and the first viable option, this scheme is still vulnerable to various known attacks. For example, an attacker could pre-hash a vast amount of passwords (say 1 billion) using a list of cracked passwords as well as generating new passwords using some pre-defined rules. Armed with that list of known hash values, an attacker could then verify if a leaked password’s hash is present in his database. It is feasible, even with a modest laptop to compare billions of hash values in a few seconds. For more information, the interested reader could refer to rainbow tables.
2. Password: Salted Hash
An improvement over the previous scheme, and to counter rainbow table attacks, is to use a cryptographic salt value. A salt is a, preferably large, random value assigned to each user of a given site (value different for each user). That salt is added to the user’s password before being sent to the hash function. In doing so, even if two users have the same password, their respective password hash values will be different (since their respective salt values are different). The goal is to slow down a potential attacker as he/she will not be able to use a database of pre-computed hash values for billions of passwords. Instead, the attacker will need to call the cryptographic hash function billions of time for each user, which will slow the attack by several order of magnitude. For example, instead of a day of compute time to crack a million passwords, the attacker might need a few years instead.
While it is still possible to target one given user account, the cracking of millions of passwords from a leaked database becomes a very very lengthy task.
Note however that using a salted hash scheme is crippled if one uses the same salt value for each user. To summarize, the salt values should be long, randomly generated and different for each user account.
3. Password: Key stretching
One further step up is to use key stretching which further slows down a potential attack by several order of magnitude. With key stretching, the cryptographic hash function is called recursively a significant amount of times (e.g. 100,000 times) before generating the final hash value for a given password.
Key stretching, used in combination with a long random cryptographic salt different for each user, renders an attack on a leaked database of password hashes extremely hard to perform.

4. Yet another scheme: encryption
Actually, there is yet another scheme, although not an entirely advisable one. Some companies such as Adobe, encrypt (not hash) all of the user information (e.g. passwords) with a single encryption key. If an attacker manages to get a hold of the decryption key, then he/she gets immediately access to all passwords in the database. Another security / privacy issue is that the database administrator would have the ability to see all the passwords in clear text (by decrypting them).
Data Breaches
Data breaches occur rather frequently. For news about the latest breaches, one could refer to the Twitter account for the site Have I Been Pwned.
Have I Been Pwned gathers information about those breaches and offers services on its web site that allows us to check if information about our email accounts has been offered for sale on the dark web, or if our passwords, or the ones we are planning on using, are already on a list of known passwords. Have I Been Pwned maintains a database of known cracked password hashes without revealing the plain text passwords. The site has information on 10 billions pawned accounts and half a billion real world passwords previously exposed in data breaches.
Another site gathering information on data breaches is Hashes.org which maintains a database of 3.5 billions cracked password hashes as well as 1 billion uncracked hashes.
Data breaches are doomed to happen. One issue that renders a breach problematic is that cryptographic hash functions that are known to be insecure are still in use today. For example, the MD5 function has been demonstrated to be insecure as early as 2005. It was shown that collisions (text that hash to the same value as the unknown password) could be found in seconds. With such an exploit, the real password is not needed anymore as the new collision text found is sufficient to gain access to the desired account (since its hash will match the one stored in the targeted system). Even though MD5 should have been abandoned shortly after 2005, some companies, such as Yahoo, Cisco, McAfee and Symantec did not update their system. In 2015, some 200 million Yahoo credentials went up for sale.
Another popular cryptographic hash function, SHA-1, has been deprecated in 2011 by NIST, with an insecurity demonstrated in 2017. Consequently, it should also not be used anymore.
The largest known data breaches are from Quora in December 2018, with 100 million user accounts affected by a data breach, Facebook saw 90 million accounts affected in September 2018 and the largest was 3 billion Yahoo user accounts being breached in 2017. For Yahoo, the information released consisted in names, email addresses, telephone numbers, encrypted and unencrypted security questions and the corresponding answers, dates of birth and finally hashed passwords.
Password Cracking
When a data breach occurs, the released information usually consists in a file, potentially with millions of entries, with each line representing information about a user: his/her user name (such as an email to gain access to a given site) and the corresponding hash value of the password.
Cracking passwords consists in recovering the text (password) corresponding to a given hash value. With such information, one can access the user account on the targeted website.
1. Brute Force
The first basic straightforward approach is brute force, which consists in trying out all possible combinations of characters. This is feasible, and can be performed extremely fast, for passwords up to 8 characters. This approach would be used when targeting one given user account and is adequate when the length of the password is relatively small (e.g. 8 characters) or alternatively when having access to large computing power (e.g. a network of computers).
Some 20 years ago, in 1998, a single machine called Deep Crack was designed to test the robustness of the DES standard. At that time, it took less than 3 days to crack a given message, and the machine was able to test 90 billion keys per second.
More recently, in 2012, a 25 GPU cluster could crack every standard Windows password in less than 6 hours.
There were also distributed efforts like distributed.net, a distributed computing project, where volunteers donate the power of their home computers when not in use (nights) to tackle a given project, such as testing the strength of a given encryption standard like RC5.
2. Lexicon + rules
The brute force approach is not feasible when one wishes to attack the millions of passwords that can be found in a typical data breach. Therefore, the second approach uses our domain knowledge in order to build up a list of feasible passwords to try (rather than an exhaustive search of all the possible passwords).
That list is first initialized with real life passwords that have been leaked to the outside world. Remember that companies such as T-mobile Australia did not bother, until recently (2018), to hash/encrypt the passwords. Also due to some software bugs, some companies may inadvertently store passwords in clear text (such as 300 million Twitter passwords). One can start with, in the order of, 1 billion real world passwords with data gathered from leaks by sites such as hashes.org. One can also gather ordinary language dictionaries.
Next is using knowledge on human behaviour in order to design some rules to transform each and every of those words present in the initial list. Rules include capitalizing the first and/or last letter of a word (secret –> Secret, secreT, SecreT), adding numbers at the end of a word (secret –> secret123), and replacing some well defined characters with their identical looking digit (hello –> he11o, h3llo, hell0). Those transformations yield some additional potential passwords to check.
There are open source tools, such as John the Ripper and Hashcat, that offer, among other types, those dictionary based attacks.
3. Language models
As humans are keen on re-using passwords and are predictable in the transformations they apply to existing dictionary words, the lexicon based approaches as implemented in John the Ripper and Hashcat are very efficient in retrieving (cracking) a large proportion of the password hashes found in data breaches.
For those remaining passwords that are not found by ‘basic’ dictionary + rules approaches, there is a need to generate large amount of feasible passwords. However, recall that we do not wish to make an exhaustive search (as in brute-force), as this would be prohibitively expensive with respect to computing resources.
One solution is to train a statistical language model using, as training data, the vast amount of cracked leaked passwords at our disposal. Once trained, the model is then used to generate huge quantities (in the billions) of feasible passwords (according to the language model). Note that a lot of those passwords will not be present in existing lexicons. Consequently, they can complement the lexicon based approaches by providing additional passwords to check.
Previously (not so long ago), language models were based on n-grams and Markov models (e.g. Language modelling notes). Nowadays, language models are built using artificial neural networks. For an interesting article on building a language model to generate passwords, the reader might look into this 2016 paper and its associated code implementation. As for a tutorial on building a character level recurrent neural networks (that would be used to train a password language model), there is a interesting PyTorch notebook available.
4. Generative Adversarial Networks (GANs)
With regard to generative models (systems able to generate new unseen data), one should not omit the relatively new scheme that are Generative Adversarial Networks (GANs). Originally, and usually, GANs are trained on a set of images and subsequently used to generate new unseen images that “live” in the same subspace as the training images. A typical example is generating new human faces such as the paper from NVIDIA on Progressive GANs published in 2018, and StyleGANs in early 2020. Some of those randomly generated images are displayed below. Using StyleGANs, you can see additional randomly generated and realistic images of persons and cats using the websites thispersondoesnotexist.com and thiscatdoesnotexist.com.

Lately, GANs have also been applied to natural language processing tasks, with papers such as SeqGAN in 2017 and Adversarial Text Generation in 2018. In 2019, PassGAN (code), used such an approach to model and consequently generate realistic passwords that could then be fed to a dictionary based attack.
To summarize, generative models (language models and GANs) are used to augment dictionary tools such as John The Ripper and Hashcat by providing billions of unseen and realistic passwords.
Toward Better Passwords
Now towards generating better passwords for ourselves that are less likely to be cracked by the aforementioned tools. The picture from xkcd.com (shown below) summarizes the issues and the solution extremely well.
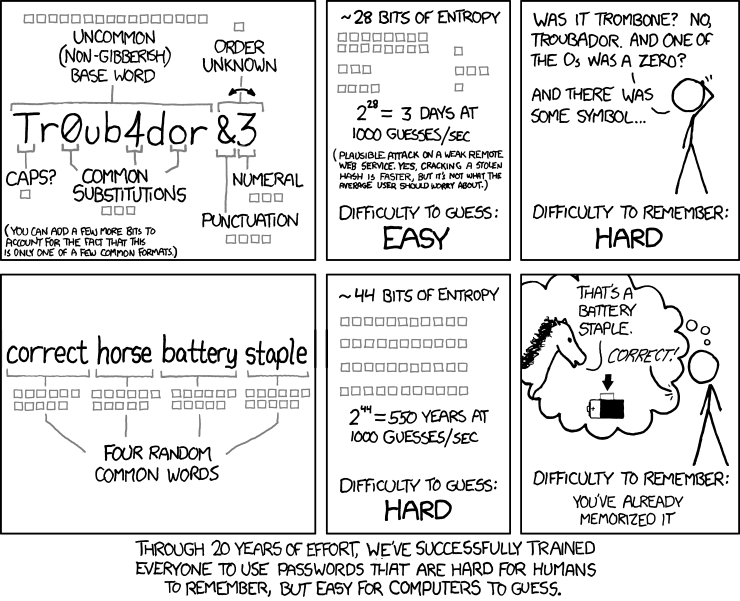
One issue is that we are often asked (required) to create passwords containing uppercase letters, numbers and special characters, while sometimes limiting the password’s length to be between 8 and 20 characters. Both of those constraints are wrong.
First, on the issue of password length, while it is a no-brainer that passwords have to be longer than 8 characters, there should not be any restrictions on the upper limit for that length. Certainly, 20 characters is way too short for the kind of strong passwords we wish to generate for ourselves: passphrases.
Second, on the issue of requiring uppercase letters, digits and special characters, humans are highly predictable. This predictability is translated into rules for dictionary based attacks. For instance, most of the time, people will uppercase the first or last letter of the word. As for numbers, they will either add a number after a word or change certain letters (in a predictable way) for certain similar looking numbers. Regarding special characters, only a handful represent the vast majority of occurrences in passwords, and these are usually found in predictable positions, following well defined rules such as replacing a letter ‘a’ with the ‘@’ character, or a letter ‘l’ with the exclamation point.
{kind=link}
As depicted in the diagram from xkcd.com above, a password strength is a function of length and unpredictability. The length of a password should definitely be longer than 8 characters. If that’s not the case, by a brute force attack, it can be cracked in seconds. The unpredictability of a password refers to the notion of entropy in information theory. (For a great visual introduction to entropy, Christopher Olah’s blog post is highly recommended.)
In order to create a very strong password (that will also be easy to remember for a human), one can visualize some image and describe it with at least 4 words. Those words should not be expected to occur together in a “normal” text (not very likely to be generated by a language model). From the xkcd diagram above, one can create the passphrase “correct horse battery staple”. Notice that those words do not usually appear together in a sentence, and are not really related. The word ‘stable’ would have been more related to ‘horse’ than ‘staple’. Hence ‘horse staple’ has a higher entropy (more of a surprise effect, less likely) than ‘horse stable’. Another example would be “submarine balloon cloud goeland” describing the image below:

This idea is relatively old (Arnold Reinhold’s Diceware - 1995). Such passphrases have a high entropy and are consequently very hard to crack. Note that no capital letters, digits and special characters were used when creating those passphrases. They are simply not required for a very strong and easy to remember password.
Password Management Tool
Part of a good password hygiene is to use a different password for each site / account that we have. It is hard (impossible) to do so without resorting to a password manager.
Password managers range from open source, freemium and commercial. Some examples applications are BitWarden (open source), NordPass (freemium), 1Password (commercial) and Apple’s iCloud Keychain functionality on iOS and macOS devices. They have extension for the popular browsers which makes it practical and effortless to log onto our accounts. Furthermore, some also offer two-factor authentication for increased security. Do your research, and choose one that you trust.
Multi-factor authentication
Multi-factor authentication refers to the notions of:
- Something you have: a physical object like a bank card, a key, a USB stick, …
- Something you know: a password, a Personal Identification Number (PIN), …
- Something you are: physical characteristics of a person (biometrics) like a fingerprint, a face (scan), voice print, typing speed, …
- Somewhere you are: GPS signal to identify your location, a specific computing network connection, …
Two-factor identification
Access to our accounts should not rely solely on a password (something we know). It should also require at least a second authentication factor. Nowadays, a lot of sites offer the option of requiring two factor authentication to log onto their services like for example, password managers (BitWarden), email accounts (Gmail, ProtonMail).
The dominant multi-factor authentication method for consumer facing accounts is a code sent to an email address or an SMS sent to our phone. While those are better than no second factor at all, as always, there are some issues. If we give our main email account for second factor authentication and its login details have just been leaked, then the attacker will get access to all of our accounts for which we gave that email address as a two-factor. For SMS, someone can (unfortunately quite easily) ‘steal’ our phone number. This attack is known as SIM porting fraud.
A better option could be to use one time password generators as a two-factor authentication. With such a scheme, a different 6 digit code is generated every 30 seconds. Twenty years ago, those codes were generated by physical devices such as the RSA SecurID (still in use). Today, one has the option of using free software apps that we can install on our mobile devices (phones, AppleWatch) such as Authy, Google Authenticator or FreeOTP to name a few.
Virtual Private Networks (VPNs)
Once we have crafted a strong password, it is important not to reveal that password in the open. One situation where that might happen is when using free open public Wi-Fis such as when visiting our favourite coffee shop. It is rather really easy, even for a 7-year old to snoop on our web traffic (e.g. typing) and steal our valuable information (e.g. login information, passwords, etc…).
Therefore, when logging into public Wi-Fi, one should use a Virtual Private Network (VPN) software. Nowadays, they are extremely easy to use (just an app installed on the phone). There are free options (sufficient when logging onto public Wi-Fis) such as ProtonVPN (which also offers a paid version for more options on server locations), or paid options such as NordVPN or ExpressVPN.
Resources
- Credentials compromised?: Pawned email addresses, Pawned passwords
- Leaked passwords lists: hashes.org, Openwall wordlists collections
- Tools: John the Ripper, Hashcat, Aicrack-ng, Neural Language Model, PassGAN Language Model
- Advice:
- Use a different password for each account / web site
- Use a passphrase instead of a password (Snowden, Better passwords, Information entropy)
- Use a password management tool (e.g. Bitwarden (open source), NordPass, 1Password)
- Use two factor identification (e.g. Authy, Google Authenticator, FreeOTP)
- Use a VPN app on public Wi-Fis: ProtonVPN, NordVPN, ExpressVPN
- Watch Edward Snowden’s video on passwords
- Bonus: Get familiar with entropy (information theory)
- Entropy: measure of how surprised we are about the next character or word
- Chris Olah’s post (highly recommended): Visual Information Theory
- Better Master Passwords: The geek edition (1Password)